|
|
|
|
|
|
|
Utilitários para manipulação de textos |
Manipulação e processamento de textos em Linux é extremamente importante, pois quase todos os documentos são de uma forma ou de outra textos. Programas fonte, arquivos de configuração, imagens [20], tabelas de bancos de dados, logs do sistema, correio eletrônico (e-mails), ou mesmo documentos para publicação (troff, TeX, lout), são na maioria das vezes simples textos. Esta generalidade, que aparenta ser restritiva, na realidade resulta numa maior facilidade no processamento desses arquivos, melhor visualização do seu conteúdo e muitas vezes economia de espaço. Por exemplo, um arquivo .xpm é na maioria das vezes metade do tamanho de um arquivo .bmp (usado pelo MS-Windows), mais facilmente editado, e pode ser diretamente incorporado a um programa C como estrutura de dado.
O modo mais direto de se processar um texto é via um editor de textos
(claro!), e para isso, já temos o nosso amigo joe. Os
usuários com tradição em uso do Unix, certamente
escolherão o vi (ou o emacs, mas não
vamos provocar uma guerra aqui!). Estes dois últimos têm suas
virtudes e são muitos mais completos que o nosso joe. Mas
para nós, mortais, que já sofremos bastante tempo com "aquele"
sistema operacional de brinquedo, como falamos no início, podemos ser
mais modestos na nossa escolha. Entretanto processamento de texto não
é somente uma edição interativa. Podemos realizar
transformações múltiplas simultâneas em um arquivo,
separar o arquivo em vários, converter em formas diferentes, ordenar,
etc. Vejamos alguns dos programas que realizam tais proezas.
|
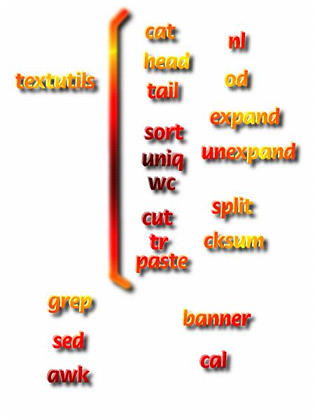
processamento e manipulação de textosMuitos dos comandos tradicionais do Unix se encontram no pacote "GNU textutils". Outros são fornecidos separadamente, mas quase sempre sob o nome "GNU-alguma-coisa". Por isso mesmo, alguns preferem chamar o Linux de GNU/Linux.
Dentre os textutils,
|
Vejamos uma rápida ficha técnica dos utilitários mais
comuns (os argumentos são mostrados na forma <argumento>,
o que for opcional será colocado entre colchetes) :
|
cat [<arquivo>]
Mostra o conteúdo do arquivo (texto) que é dado como argumento.
Provavelmente, |
head [-n<linhas>] <arquivo>
Mostra as primeiras linhas do arquivo. |
tail [-n<linhas>] <arquivo>
Mostra as últimas linhas do arquivo. |
|
sort [-o<saida>] [<arquivo>]
Ordena o arquivo (ou stdin) escrevendo no stdout (opcionalmente no arquivo <saida>). |
expand [<arquivo>]
Expande tabs em espaçso e escreve em stdout. |
unexpand [<arquivo>]
Converte (quando possível) múltiplos espaços em tabs. O
contrário de |
|
uniq
Funciona como um filtro, lendo do stdin e escrevendo no stdout, removendo
linhas duplicadas. (normalmente usado após um |
wc [-clw] [<arquivo>]
Devolve número de caracteres, linhas e palavras do arquivo (ou stdin). |
cksum <arquivo>
Mostra cehcksum (CRC) e tamanho em bytes do arquivo. |
|
sort [-o<saida>] [<arquivo>]
Ordena o arquivo (ou stdin) escrevendo no stdout (opcionalmente no arquivo <saida>). |
expand [<arquivo>]
Expande tabs em espaçso e escreve em stdout. |
unexpand [<arquivo>]
Converte (quando possível) múltiplos espaços em tabs. O
contrário de |
Os utilitários cut e paste servem para extrair partes (campos) de um
arquivo e remontá-las formando um arquivo novo, com dados possivelmente
de vários outros arquivos. O comando cut pode extrair caracteres (com
-c<lista de caracteres>) ou campos (com -f<lista de
campos>), onde as listas podem ser números separados por
vírgulas ou faixas de números como n1-n2 (separados
por um hífen), ou ainda combinações de ambos. O delimitar
de campos é um único caracter, especificado como
-d<delim>.
Um exemplo ilustra melhor. Suponhamos que desejamos extrair o login (primeiro
campo) e o nome real (campo 5) dos usuários do nosso sistema. A tabela
seguinte nos mostra o efeito do comando:
arquivo /etc/passwd original
|
após cut -f1,5 -d: /etc/passwd
|
|
guest::405:100:convidado especial:/home/guest:/bin/bashrildo:gfTMTkLpLeupE:500:100:Rildo Pragana:/home/rildo:/bin/bash
postgres::65:1:Administrador do PostgreSQL:/usr/local/pgsql:/bin/bash
julius:toR8GcUaAr8h6:601:100:Julius Pragana:/home/julius:/bin/bash
|
--> |
guest:convidado especialrildo:Rildo Praganapostgres:Administrador do PostgreSQLjulius:Julius Pragana
|
O paste faz exatamente o contrário. Adiciona colunas
provenientes de dois ou mais arquivos formando um arquivo final com estes
dados. Vejamos um exemplo, usando a vírgula como delimitador:
|
arq1.txt:
|
arq2.txt:
|
|
paste -d, arq1.txt arq2.txt
|
||
|
arquivo resultante: (ou stdout)
|
banner cal e date
|

|
Programas como o grep, sed e awk, entre
outros (mesmo o nosso amigo joe), se utilizam de uma
descrição genérica de textos, na forma de padrões,
para especificar alguns de seus argumentos. Formas com wildcards,
como vimos com o shell, não são poderosas o suficientes para
definirem padrões genéricos de caracteres que desejamos
encontrar. Para isso, precisamos de uma notação mais
abrangente, que são as expressões
regulares.
Uma expressão regular descreve
uma sequência de caracteres, casando letras adjacentes. O padrão
mais simples é apenas um grupo de caracteres. Se quisermos, por
exemplo, saber se em um determinado arquivo [21] existe a palavra exemplo, o comando
grep[22]
pode nos ser útil:
~$ grep exemplo livro
de espaço. Por exemplo, um arquivo .xpm é na maioria das vezes
metade
Nesse exemplo, apenas uma ocorrência da palavra foi encontrada pelo
programa grep. A nossa expressão regular era apneas a
sequência de caracteres 'e','x','e','m','p','l','o'. De modo mais
geral, podemos incluir um '.' (ponto) para indicar um caracter qualquer.
Assim, a expressão movid.s "casa" (match em
inglês) com movidos e movidas, mas casa
também com movidxs, ou qualquer outro caracter no lugar do
ponto. Para forçar que uma posição case apenas com alguns
dentre uma classe de caracteres, podemos definir essa classe entre colchetes.
Por exemplo movid[ao]s, so dá certo com a e
o na posição dos colchetes.
Podemos definir igualmente classes que não contenham determinados
caracteres. Por exemplo, a expressão regular d[^ao]s casa
com d+<qualquer caracter exceto "a" ou "o">+s. Existem
também caracteres especiais (chamados meta-caracteres), que modificam o
comportamento de um padrão. O asterisco indica "qualquer quantidade
(zero ou mais)" do caracter ou classe que o precede. O símbolo "+"
(mais), indica "um ou mais". Exemplo: as+a casa com
asa, assa, asssssa, etc., mas
não com aa. Entretanto, por exemplo as*a pode
casar com aa (o que com o "+" não podia).
Para marcar o começo ou final de uma linha, existem dois
meta-caracteres: "^" e "$", respectivamente.
Exemplo: ^$ é uma expressão regular que só
casa com linhas em branco (inclusive sem nehum espaço ou caracter
tab).
Um problema pode nos ocorrer quando queremos casar com um destes
meta-caracteres literalmente. Exemplo, queremos procurar linhas que terminam
com um ponto (final de parágrafo?!) no nosso documento. Usaremos o
met-caracter de final de linha "$", juntamente com um ponto... Mas, espere
aí, um ponto significa "um caracter qualquer, portanto, todas as linhas
serão candidatas! Para retirar esse efeito "meta" destes caracteres
especiais, prefixamos ele com uma barra de divisão invertida
(exatamente como no shell): \.$ será nossa
expressão regular.
Uma notação complementar
serve para indicarmos "entre n e m caracteres" para o caracter ou classe
precedente: {n,m}. Exemplo queremos um ou dois carcteres s
apenas na expressão: as{1,2}a , que casa
com asa e assa e mais
nada!
A essa altura voce deve ter percebido que muitos destes caracteres e
meta-caracteres conflitam com o shell, isto é, têm significado
especial também para o shell. Portanto, voce terá que remover
esse significado efetuado o quoting das expressões ou prefixando cada
caracter especial com uma barra invertida para evitar que o shell faça
suas substituições na linha de comando, antes de dar chance ao
grep de conhecê-los.
o sed em poucas palavras
O sed, abreviatura de stream editor, é um programa que permite
a edição de documentos de forma não-interativa. Não daremos um curso completo de sed, pois ele é relativamente complexo. Apenas mostraremos exemplos que podem ser úteis no dia-a-dia. (observe que estamos colocando a expressão regular entre apóstrofes, para evitar a interpretação do shell, apesar de que neste caso nenhum caracter especial está sendo usado, mas é bom se acostumar assim...)
Troca abreviaturas de PE (Pernambuco) pelo nome completo no arquivo
Um exemplo mais sofisticado: o comando man sed | sed 's/.\^H//g' | less
o
|
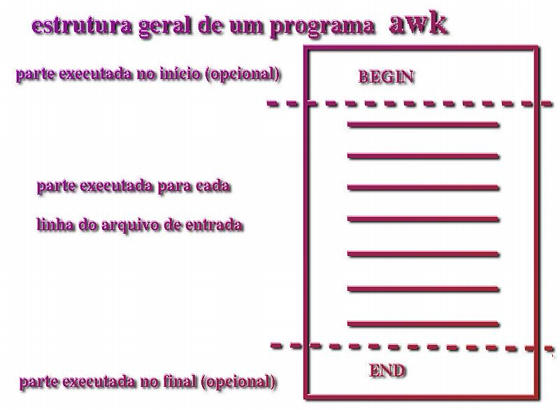
O awk é uma linguagem também com expressões
regulares, porém bem mais genérica que o sed (que
é somente um editor de textos, na realidade). Uma linha de programa em
awk é constituida de um padrão (expressão
regular) e um comando a executar caso esta expressão seja "casada".
Para cada linha do arquivo de entrada todas as expressões (linhas do
programa) são tentadas.